
Auto Enrollment, Super speedy transparent cache, Fractional CPU and Custom Billing

Actuated.com's Q4 announcements - Auto Enrollment, Super speedy transparent cache, Fractional CPU and Custom Billing.
We're releasing our Q4 announcements early and we've got a lot to share with you.
- Auto Enrollment - a single bash command and your server is ready to use and specially tuned for GCP VMs with Nested Virtualisation
- Super speedy transparent cache - a cache that works with actions/cache and BuildKit - the only limit? local NVMe SSD
- Fractional CPU - run your builds on a fractional CPU i.e. 0.25 or 0.5 vCPU to lower your costs and improve efficiency
- Custom Billing - do you need high spikes of concurrency? In addition to our concurrency plans, you can reach out for plans charged by the minute
Auto Enrollment
Before
In the past, actuated customers would pick a server, load up an OS then do the following:
- Figure out the best free disk or partition to format for microVM snapshots
- Install and configure a Docker Registry Mirror/pull-through cache
- Install the actuated agent
- Create a DNS entry for the agent
- Send us an encrypted enrollment YAML file via email or Slack
Wait for us to add the host.
After
Now, with a simple snippet in your userdata, Terraform or Ansible playbook your server will be taking jobs in a minute or two.
After it's been offline for 15 minutes, it'll get cleaned up automatically.
Yes that means you can use Managed Instance Groups (MIGs) on GCP, or your own autoscaler to scale up and down as needed.
#!/bin/bash
curl -LSsf https://get.actuated.com | \
LICENSE="" \
TOKEN="" \
LABELS="gcp-ssd" \
HOME="/root" bash -
The LICENSE is sent via email at checkout, and the TOKEN is available on request after checking out. The TOKEN is known as an Account API Token and is used for onboarding new hosts, and for gathering Prometheus metrics
A Docker Registry Mirror/pull-through cache is installed by default, but if you give a DOCKER_USERNAME and DOCKER_PASSWORD to the script, it'll use your own Docker Hub credentials to pull images to greatly increase the pull limits.
When onboarding a recent customer they'd explained they were concerned about the steps to set up a new machine. We're happy to say that this is now a single command and your server is ready to use.
We're excited by how well the new auto-enrollment works and could see it leading to an autoscaler for GCP.
Savings with spot instances
One of our customers was excited to see this announcement because it means they can switch from a pre-provisioned c4-standard-16-lssd to spot instances, and save a considerable amount of money. They can also take their runner down over the weekend and bring it back any time they like with cron.
Auto Enrollment Demo videos
- Actuated Autoenrollment on Bare-Metal Cloud with Hetzner
- Actuated Autoenrollment on Nested Virtualisation (DigitalOcean) - the same approach can be used for GCP with Terraform, Ansible, or your own custom binary
Super speedy transparent cache
This announcement is a close second favourite for us behind Auto Enrollment.
One of the number one complaints about GitHub's hosted cache is that it's slow, especially from self-hosted runners.

We've always offered the ability for you to run an S3 cache directly on your servers, and instructions on how to use forked caching actions like testpkg/actions-cache which can target S3 instead of the proprietary GitHub cache.
But, this also involved manual setup and configuration of the cache.
The new approach is completely transparent to you.
actions/cache- will now use the local cache by default- BuildKit - will now use the local cache by default
setup-node,setup-python,setup-java,setup-ruby,setup-go- will now use the local cache by default
How does it work?
All requests to GitHub's caching servers (and only those requests) are intercepted and redirected to the local machine. No changes to your workflows are required.
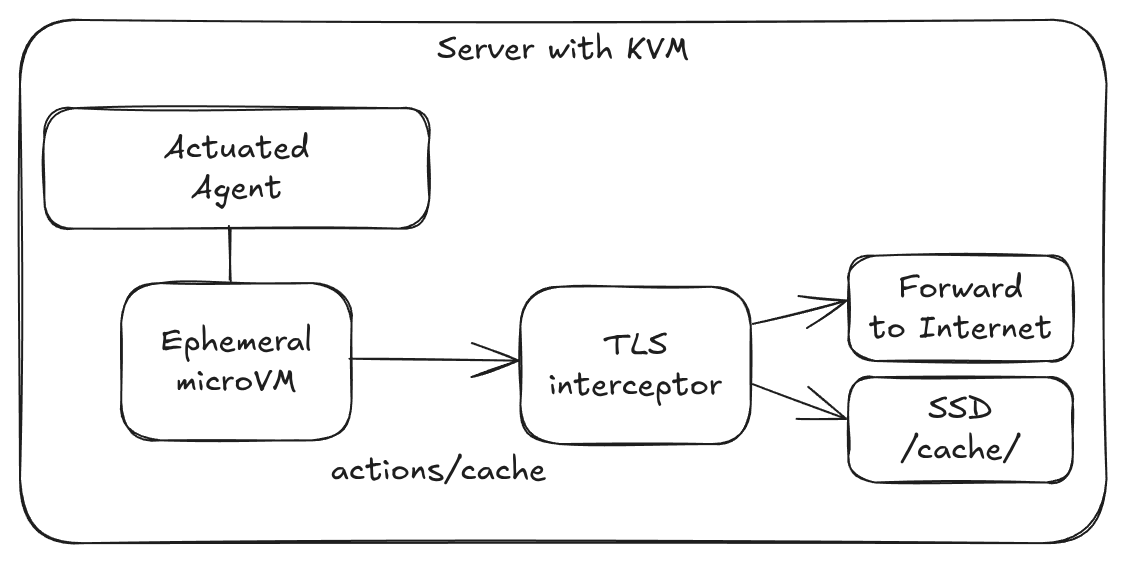
Only caching requests are redirected and intercepted, all other traffic is passed through unmodified. This code runs on your server, and our team has no access to any of your traffic. "Super speedy transparent caching" to coin a term, will be opt-in. And the more manual approach (which is just as fast, just less convenient) will still be available.
Rough speed tests:
- GCP c4-standard-4 - Saving cache ~ 100MB/s
- AMD Ryzen™ 9 9950X3D / Hetzner AX102 - 276MB/s read / 478.9MB/s write
- Intel N100 - 89.9MB/s read / 155.7MB/s write
When using a Hosted Cache on a Hosted Runner, cache saves and restores can often throttled down to 1-10MB/s.
When using a Hosted Cache with a self-hosted runner, these figures are often much lower.
Fractional CPU
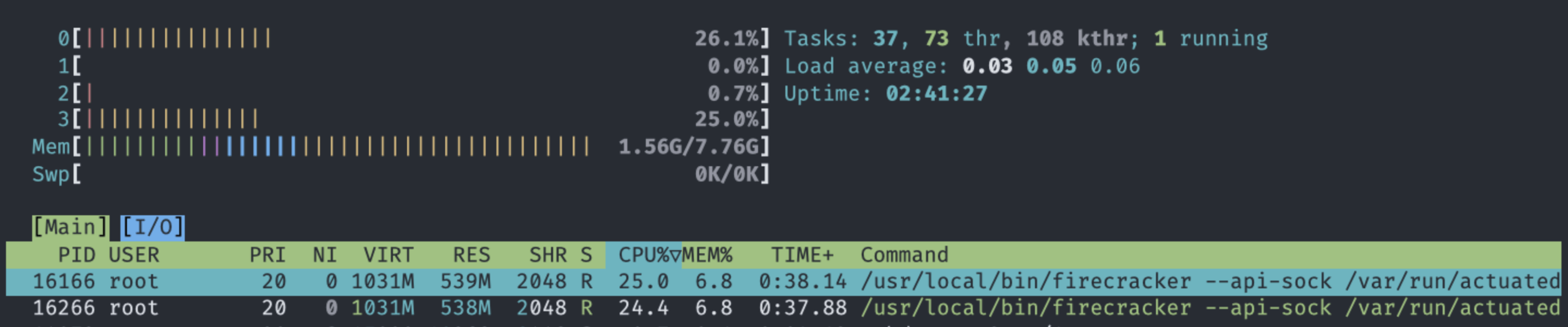
A DigitalOcean VM with 2x 0.25 vCPU actuated runners running jobs in parallel.
GitHub recommends a minimum of 2 vCPU and 8GB of RAM for its Runner which is written in C# and undergoes a Just In Time (JIT) compilation step when it starts up.
That said, since we introduced Profiling in the Actuated Dashboard, customers have noticed they can get away with much less than that, as low as actuated-1cpu-1gb.
Now, what if you have 100 jobs queued up which all perform basic automation tasks on PRs, issues, and repos?
At 1 vCPU each, a GCP c4-standard-16 could run around 16 jobs at once, but if you don't mind the extra time:
runs-on: actuated-0.25cpu-1gb- will run 64 jobs - that's 4x the amount.runs-on: actuated-0.5cpu-1gb- will run 32 jobs - that's 2x the amount.
We're also adding fractional RAM support with 512MB and 750MB being available in addition to the existing full numbers of RAM.
In practical terms, we ran a benchmark on DigitalOcean using a 4vcpu-8gb machine which is of course much smaller than we'd ever recommend for production use.
Installing stress-ng via apt took 7s with a VM with with actuated-1cpu-1gb, but when throttled to actuated-250mcpu-1gb, it took 26s.
name: stress-ng
on:
workflow_dispatch:
jobs:
stress:
runs-on: actuated-250mcpu-1gb
steps:
- name: Install
run: sudo apt install stress-ng -y
- name: Stress
run: stress-ng --cpu 1 --cpu-load 100 --timeout 2m
We have to remember that this system is configured to be multi-threaded - it uses systemd as its init, and runs the Actions Runner, on top of any other steps you need. So while 0.25 vCPU is not going to be as fast as 1 vCPU, it's still perfectly usable for many workloads.
What does this mean?
You get bin packing - the ability to run many more concurrent jobs, but at the cost of lower performance for those jobs.
Should you use it for a production build or a critical Terraform deployment? Probably not.
But if you're interacting with GitHub events, running linters, or bash scripts via a schedule - fractional CPU can save you a lot of money.
Custom Billing for large teams with spiky workloads
This year, we revisited the pricing for actuated and now offer two plans: Concurrency based plans - from 250 USD / month and Custom Billing.
Concurrency based plans
Servers: no limit Minutes: no limit vCPU: no limit RAM: no limit
Charges: maximum concurrent builds
This mode is a great place to start because the pricing is flat-rate and predictable. It never needs to change or spike, even if you have a large backlog to run through.
Our pricing calculator shows how easy it is to save money compared to GitHub's hosted runners, especially once you start needing more than 2x vCPU for jobs.
One customer told us they were running 36,000 builds per month on 4 vCPU Hosted Runners, costing them 1,440 USD per month.
With actuated's pricing calculator, that works out at roughly 1/2 of the price with a 10 concurrent build plan.
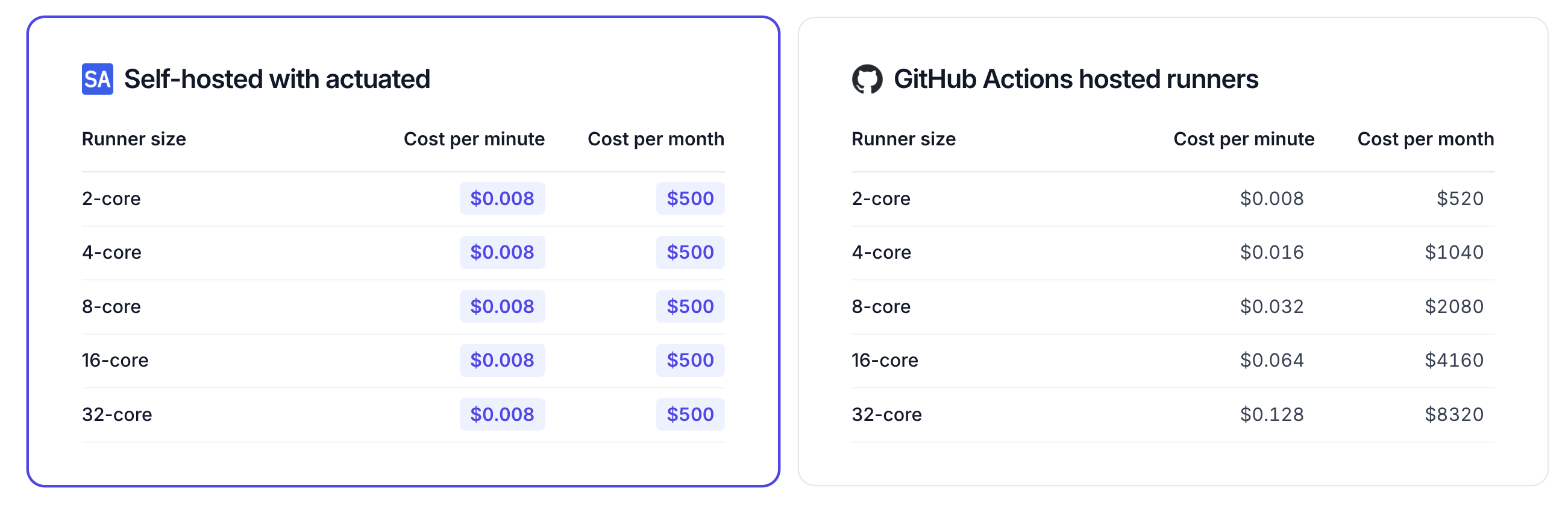
If they upgraded to 8 vCPU hosted runners their bill would have been 2,880 USD per month with GitHub, and 4x cheaper with actuated.
Custom Billing
With Custom Billing, we'll do our best to work out a plan that scales with your organisation's needs.
So if you ran 3,600,000 minutes per month, that'd be $28,800 USD per month on GitHub's smallest 2vCPU machines, and $57600 USD per month with a 4 vCPU runners.
Now clearly, if you also needed around 400 concurrent builds - actuated's concurrency based plan would not scale, so we'd work out a factor that lets us both grow together whether that's based upon:
- total minutes,
- total servers,
- or a graduated concurrency-based pricing model.
Custom Billing is available for any customer that needs more than 50 concurrent builds per month.
Wrapping up
On top of our previous announcement this month Actuated for Jenkins, we're excited to be able to offer you a more flexible and scalable way to run your CI/CD workflows.
You can be running jobs within a few minutes:
- Checkout on the pricing page - either book a call to talk to us, or go 100% self-service (both come with access to Slack during business hours)
- Deploy a bare-metal server on Hetzner Robot for the best price/performance ratio, or launch a VM on GCP, Azure, or Oracle Cloud with Nested Virtualisation enabled
- Obtain your Account API Token, and run the auto-enrollment script
- Change the
runs-on:label to i.e.actuated-4cpu-16gband start running jobs
Want to learn more? Talk to us on a call.
You may also like: