
The state of Arm CI for the CNCF

After running almost 400k build minutes for top-tier CNCF projects, we give an update on the sponsored Arm CI program.
It's now been 4 months since we kicked off the sponsored program with the Cloud Native Computing Foundation (CNCF) and Ampere to manage CI for the foundation's open source projects. But even before that, Calyptia, the maintainer of Fluent approached us to run Arm CI for the open source fluent repos, so we've been running CI for CNCF projects since June 2023.
Over that time, we've got to work directly with some really bright, friendly, and helpful maintainers, who wanted to have a safe, fast and secure way to create release artifacts, test PRs, and to run end to end tests. Their alternative until this point was either to go against GitHub's own advice, and to run an unsafe, self-hosted runner on an open source repo, or to use QEMU that in the case of Fluent meant their 5 minute build took over 6 hours before failing.
You can find out more about why we put this program together in the original announcement: Announcing managed Arm CI for CNCF projects
Measuring the impact
When we started out, Chris Aniszczyk, the CNCF's CTO wanted to create a small pilot to see if there'd be enough demand for our service. The CNCF partnered with Ampere to co-fund the program, Ampere sell a number of Arm based CPUs - which they brand as "Cloud Native" because they're so dense in cores and highly power efficient. Equinix Metal provide the credits and the hosting via the Cloud Native Credits program.
In a few weeks, not only did we fill up all available slots, but we personally hand-held and onboarded each of the project maintainers one by one, over Zoom, via GitHub, and Slack.
Why would maintainers of top-tier projects need our help? Our team and community has extensive experience porting code to Arm, and building for multiple CPUs. We were able to advise on best practices for splitting up builds, how to right-size VMs, were there to turn on esoteric Kernel modules and configurations, and to generally give them a running start.
Today, our records show that the CNCF projects enrolled have run almost 400k minutes. That's almost the equivalent of a computer running tasks 24/7 for a total of 2 months solid, without a break.
Here's a list of the organisations we've onboarded so far, ordered by the total amount of build minutes. We added the date of their first actuated build to help add some context. As I mentioned in the introduction, fluent have been a paying customer since June 2023.
| Rank | Organisation | Date of first actuated build |
|---|---|---|
| 1 | etcd-io (etcd, boltdb) | 2023-10-24 |
| 2 | fluent | 2023-06-07 |
| 3 | falcosecurity | 2023-12-06 |
| 4 | containerd | 2023-12-02 |
| 5 | cilium (tetragon, cilium, ebpf-go) | 2023-10-31 |
| 6 | cri-o | 2023-11-27 |
| 7 | open-telemetry | 2024-02-14 |
| 8 | opencontainers (runc) | 2023-12-15 |
| 9 | argoproj | 2024-01-30 |
Ranked by build minutes consumed
Some organisations have been actuated on multiple projects like etcd-io, with boltdb adding to their minutes, and cilium where tetragon and ebpf-go are also now running Arm builds.
It's tempting to look at build minutes as the only metric, however, now that containerd, runc, cilium, etcd, and various other core projects are built by actuated, the security of the supply chain has become far more certain.
From 10,000ft
Here's what we aimed for and have managed to achieve in a very short period of time:
- Maintainers have no infrastructure to maintain - in the case of etcd, 5 people are now off the hook for being on call to manually maintain servers
- OSS projects can run their CI jobs securely on ephemeral runners, with no risk of side-effects
- Equinix Metal that donates credits has reduced the total amount of servers allocated and greatly increased utilization
Making efficient use of shared resources
After fluent, etcd was the second project to migrate off self-managed runners. They had the impression that one of their jobs needed 32 vCPU and 32GB of RAM, and when we monitored the shared server pool, we noticed barely any load on the servers. That led me to build a quick Linux profiling tool called vmmeter. When they ran the profiler, it turned out the job used a maximum of 1.3 vCPU and 3GB of RAM, that's not just a rounding error - that's a night and day difference.
You can learn how to try out vmmeter to right-size your jobs on actuated, or on GitHub's hosted runners.
Right sizing VMs for GitHub Actions
The projects have had a fairly stable, steady-state of CI jobs throughout the day and night as contributors from around the globe send PRs and end to end tests run.
But with etcd-io in particular we started to notice on Monday or Tuesday that there was a surge of up to 200 jobs all at once. When we asked them about this, they told us Dependabot was the cause. It would send a number of PRs to bump dependencies and that would in turn trigger dozens of jobs.
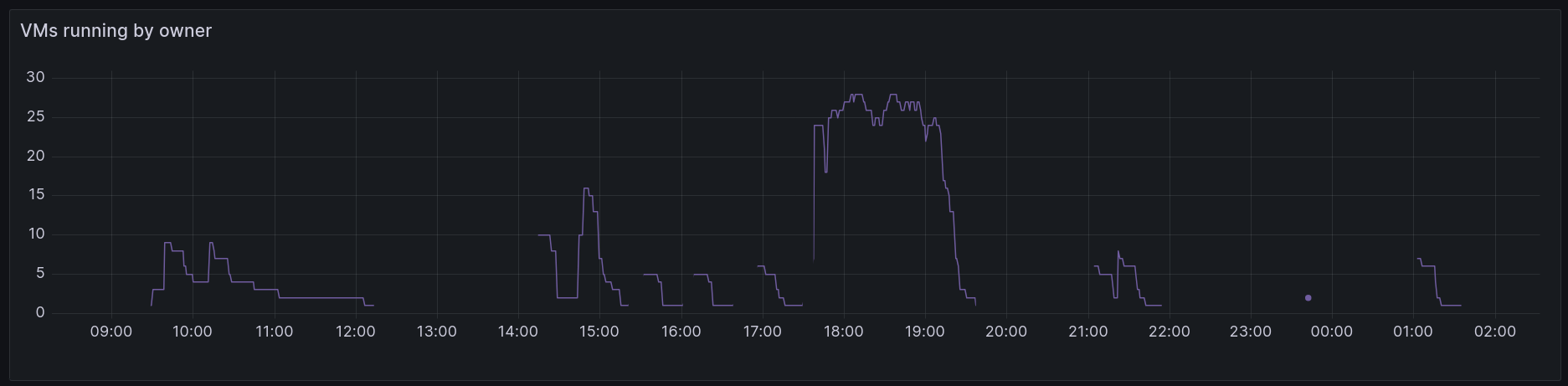
Thundering herd problem from dependabot
It would clear itself down in time, but we spent a little time to automate adding in 1-2 extra servers for this period of the week, and we managed to get the queue cleared several times quicker. When the machines are no longer needed, they drain themselves and get deleted. This is important for efficient use of the CNCF's credits and Equinix Metal's fleet of Ampere Altra Q80 Arm servers.
Giving insights to maintainers
I got to meet up with Phil Estes from the containerd project at FOSDEM. We are old friends and used to be Docker Captains together.
We looked at the daily usage stats, looked at the total amount of contributors that month and how many builds they'd had.

Then we opened up the organisation insights page and found that containerd had accounted for 14% of the total build minutes having only been onboarded in Dec 2023.
We saw that there was a huge peak in jobs last month compared to this month, so he went off to the containerd Slack to ask about what had happened.
Catching build time increases early
Phil also showed me that he used to have a jimmy-rigged dashboard of his own to track build time increases, and at FOSDEM, my team did a mini hackathon to release our own way to show people their job time increases.
We call it "Job Outliers" and it can be used to track increases going back as far as 120 days from today.
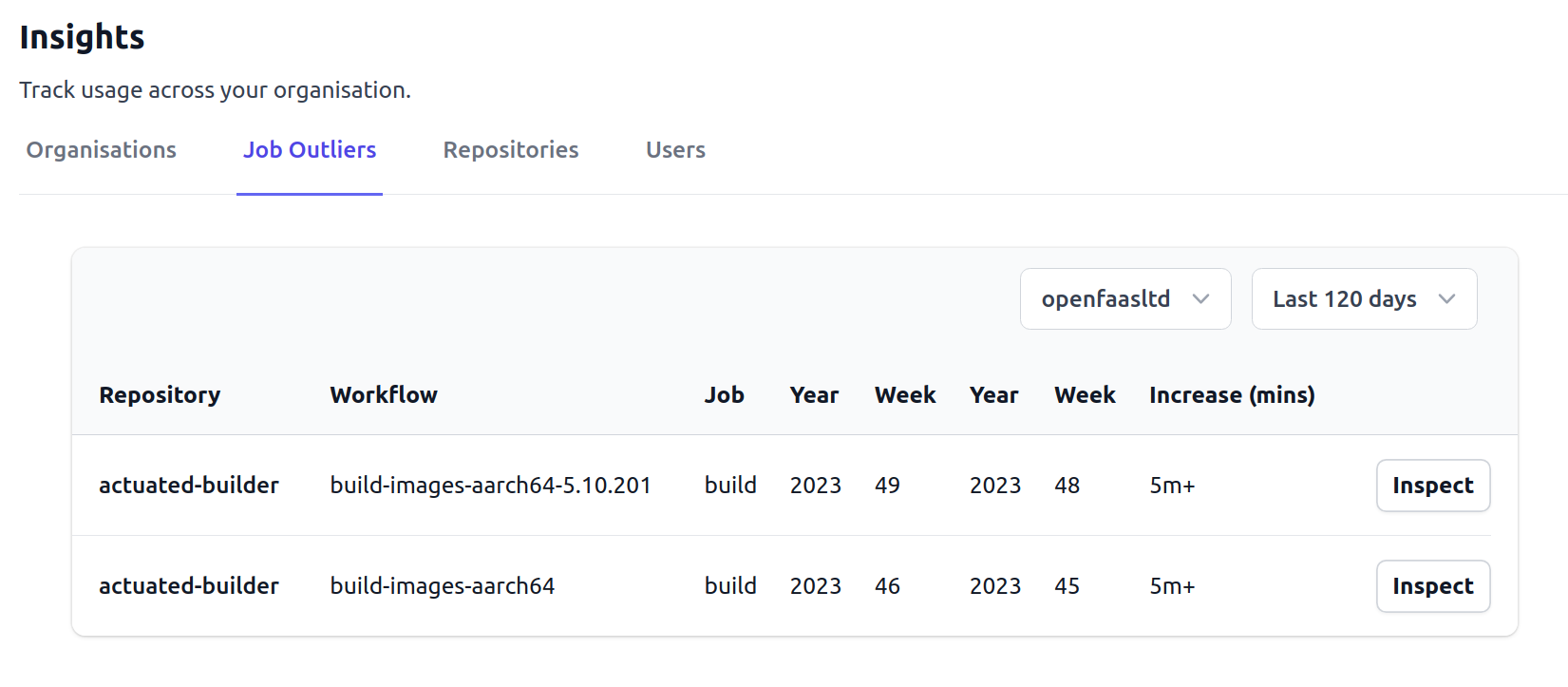
Clicking "inspect" on any of the workflows will open up a separate plot link with deep links to the longest job seen on each day of that period of time.
So what changed for our own actuated VM builds in that week, to add 5+ minutes of build time?
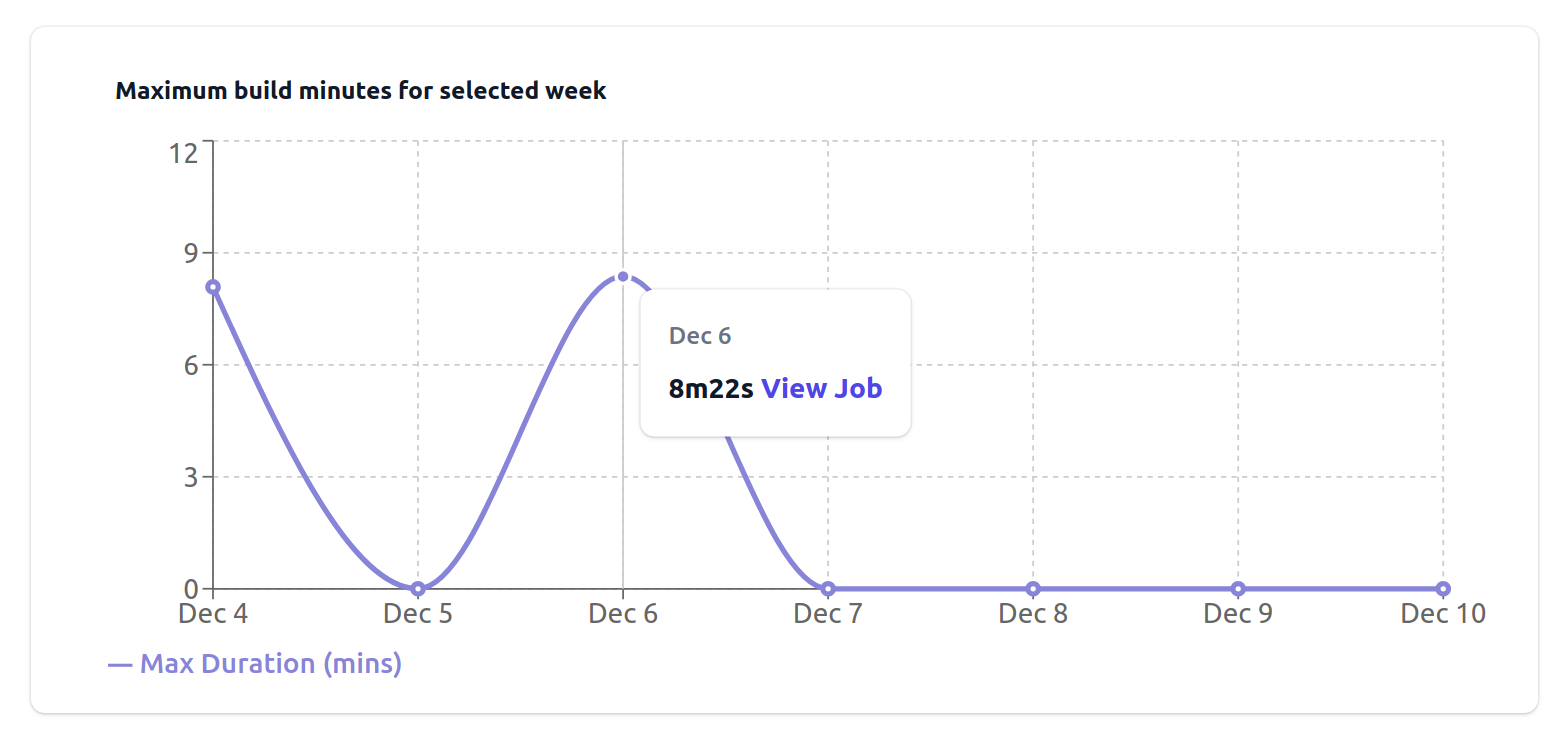
We started building eBPF into the Kernel image, and the impact was 2x 2.5 minutes of build time.
This feature was originally requested by Toolpath, a commercial user of actuated with very intensive Julia builds, and they have been using it to keep their build times in check. We're pleased to be able to offer every enhancement to the CNCF project maintainers too.
Wrapping up
What are the project maintainers saying?
Antoine Toulme, maintainer of OpenTelemetry collectors:
The OpenTelemetry project has been looking for ways to test arm64 to support it as a top tier distribution. Actuated offers a path for us to test on new operating systems, especially arm64, without having to spend any time setting up or maintaining runners. We were lucky to be the recipient of a loan from Ampere that gave us access to a dedicated ARM server, and it took us months to navigate setting up dedicated runners and has significant maintenance overhead. With Actuated, we just set a tag in our actions and everything else is taken care of.
Luca Guerra, maintainer of Falco:
Falco users need to deploy to ARM64 as a platform, and we as maintainers, need to make sure that this architecture is treated as a first class citizen. Falco is a complex piece of software that employs kernel instrumentation and so it is not trivial to properly test. Thanks to Actuated, we were able to quickly add ARM64 to our GitHub Actions CI/CD pipeline making it much easier to maintain, freeing up engineering time from infrastructure work.
Sascha Grunert, maintainer of Cri-o:
The CRI-O project was able to seamlessly integrate Arm based CI with the support of Actuated. We basically had to convert our existing tests to a GitHub Actions matrix utilizing their powerful Arm runners. Integration and unit testing on Arm is another big step for CRI-O to provide a generally broader platform support. We also had to improve the test suite itself for better compatibility with other architectures than x86_64/arm64. This makes contributing to CRI-O on those platforms even simpler. I personally don’t see any better option than Actuated right now, because managing our own hardware is something we’d like to avoid to mainly focus on open source software development. The simplicity of the integration using Actuated helped us a lot, and our future goal is to extend the CRI-O test scenarios for that.
Summing up the program so far
Through the sponsored program, actuated has now almost 400k build minutes for around 10 CNCF projects, and we've heard from a growing number of projects who would like access.
We've secured the supply chain by removing unsafe runners that GitHub says should definitely not be used for open source repositories, and we've lessened the burden of server management on already busy maintainers.
Whilst the original pilot program is now full, we have the capacity to onboard many other projects and would love to work with you. We are happy to offer a discounted subscription if your employer that sponsors your time on the said CNCF project will pay for it. Otherwise, contact us anyway, and we'll put you into email contact with Chris Aniszczyk so you can let him know how this would help you.