
Accelerate GitHub Actions with dedicated GPUs

You can now accelerate GitHub Actions with dedicated GPUs for machine learning and AI use-cases.
With the surge of interest in AI and machine learning models, it's not hard to think of reasons why people want GPUs in their workstations and production environments. They make building & training, fine-tuning and serving (inference) from a machine learning model just that much quicker than running with a CPU alone.
So if you build and test code for CPUs in CI pipelines like GitHub Actions, why wouldn't you do the same with code built for GPUs? Why exercise only a portion of your codebase?
GPUs for GitHub Actions
One of our earliest customers moved all their GitHub Actions to actuated for a team of around 30 people, but since Firecracker has no support for GPUs, they had to keep a few self-hosted runners around for testing their models. Their second hand Dell servers were racked in their own datacentre, with 8x 3090 GPUs in each machine.
Their request for GPU support in actuated predated the hype around OpenAI, and was the catalyst for us doing this work.
They told us how many issues they had keeping drivers in sync when trying to use self-hosted runners, and the security issues they ran into with mounting Docker sockets or running privileged containers in Kubernetes.
With a microVM and actuated, you'll be able to test out different versions of drivers as you see fit, and know there will never be side-effects between builds. You can read more in our FAQ on how actuated differs from other solutions which rely on the poor isolation afforded by containers. Actuated is the closest you can get to a hosted runner, whilst having full access to your own hardware.
I'll tell you a bit more about it, how to build your own workstation with commodity hardware, or where to rent a powerful bare-metal host with a capable GPU for less than 200 USD / mo that you can use with actuated.
Available in early access
So today, we're announcing early access to actuated for GPUs. Whether your machine has one GPU, two, or ten, you can allocate them directly to a microVM for a CI job, giving strong isolation, and the same ephemeral environment that you're used to with GitHub's hosted runners.

Our test rig has 2x Nvidia 3060 GPUs and is available for customer demos and early testing.
We've compiled a list of vendors that provide access to fast, bare-metal compute, but at the moment, there are only a few options for bare-metal with GPUs.
- Self-build a workstation, you'll recover the total cost in < 1 month vs hosted
- Use a European bare-metal host like Hetzner or OVH Cloud
We have a full bill of materials available for anyone who wants to build a workstation with 2x Nvidia 3060 graphics cards, giving 24GB of usage RAM at a relatively low maximum power consumption of 170W. It's ideal for CI and end to end testing.
If you'd like to go even more premium, the Nvidia RTX 4000 card comes with 20GB of RAM, so two of those would give you 40GB of RAM available for Large Language Models (LLMs).
For Hetzner, you can get started with an i5 bare-metal host with 14 cores, 64GB RAM and a dedicated Nvidia RTX 4000 for around 184 EUR / mo (less than 200 USD / mo). If that sounds like ridiculously good value, it's because it is.
What does the build look like?
Once you've installed the actuated agent, it's the same process as a regular bare-metal host.
It'll show up on your actuated dashboard, and you can start sending jobs to it immediately.
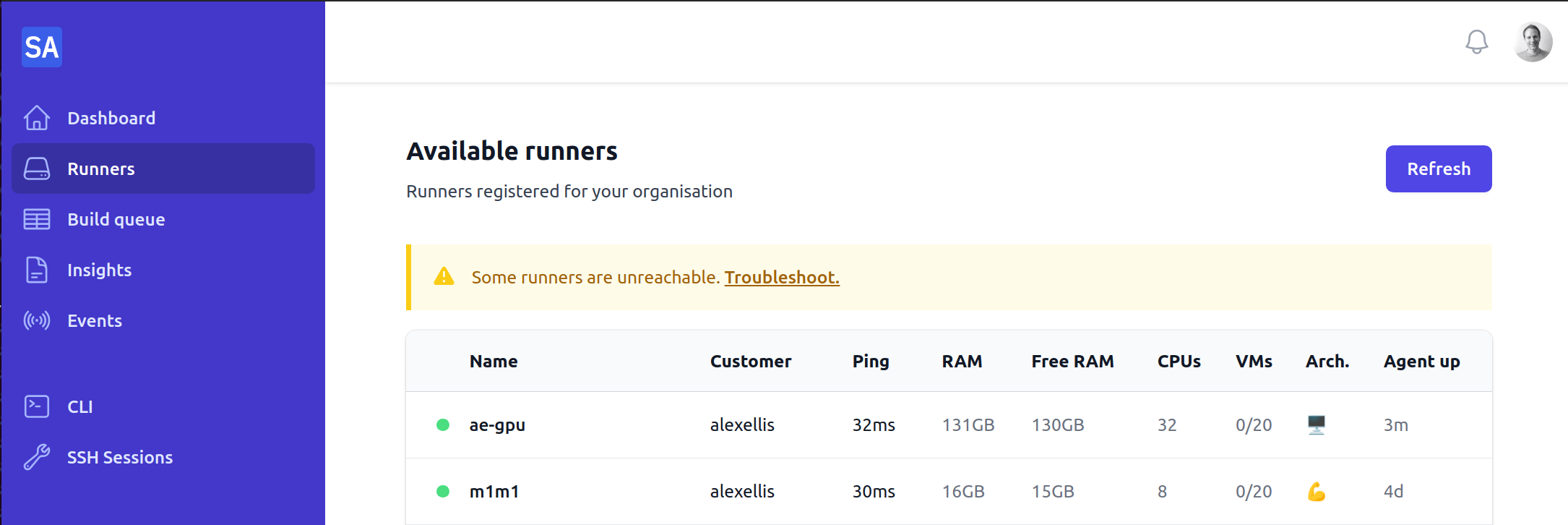
The server with 2x GPUs showing up in the dashboard
Here's how we install the Nvidia driver for a consumer-grade card. The process is very similar for the datacenter range of GPUs found in enterprise servers.
name: nvidia-smi
jobs:
nvidia-smi:
name: nvidia-smi
runs-on: [actuated-8cpu-16gb, gpu]
steps:
- uses: actions/checkout@v1
- name: Download Nvidia install package
run: |
curl -s -S -L -O https://us.download.nvidia.com/XFree86/Linux-x86_64/525.60.11/NVIDIA-Linux-x86_64-525.60.11.run \
&& chmod +x ./NVIDIA-Linux-x86_64-525.60.11.run
- name: Install Nvidia driver and Kernel module
run: |
sudo ./NVIDIA-Linux-x86_64-525.60.11.run \
--accept-license \
--ui=none \
--no-questions \
--no-x-check \
--no-check-for-alternate-installs \
--no-nouveau-check
- name: Run nvidia-smi
run: |
nvidia-smi
This is a very similar approach to installing a driver on your own machine, just without any interactive prompts. It took around 38s which is not very long considering how much time AI and ML operations can run for when doing end to end testing. The process installs some binaries like nvidia-smi and compiles a Kernel module to load the graphics driver, these could easily be cached with GitHub Action's built-in caching mechanism.
For convenience, we created a composite action that reduces the duplication if you have lots of workflows with the Nvidia driver installed.
name: gpu-job
jobs:
gpu-job:
name: gpu-job
runs-on: [actuated-8cpu-16gb, gpu]
steps:
- uses: actions/checkout@v1
- uses: self-actuated/nvidia-run@master
- name: Run nvidia-smi
run: |
nvidia-smi
Of course, if you have an AMD graphics card, or even an ML accelerator like a PCIe Google Corale, that can also be passed through into a VM in a dedicated way.
The mechanism being used is called VFIO, and allows a VM to take full, dedicated, isolated control over a PCI device.
A quick example to get started
To show the difference between using a GPU and CPU, I ran OpenAI's Whisper project, which transcribes audio or video to a text file.
With the following demo video of Actuated's SSH gateway, running with the tiny model.
- A AMD Ryzen 9 5950X 16-Core Processor took 39 seconds
- The same host with a 3060 GPU mounted via actuated took 16 seconds
That's over 2x quicker, for a 5:34 minute video. If you process a lot of clips, or much longer clips then the difference may be even more marked.
The tiny model is really designed for demos, and in production you'd use the medium or large model which is much more resource intensive.
Here's a screenshot showing what this looks like with the medium model, which is much larger and more accurate:
Medium model running on a GPU via actuated
Medium model running on a GPU via actuated
With a CPU, even with 16 vCPU, all of them get pinned at 100%, and then it takes a significantly longer time to process.
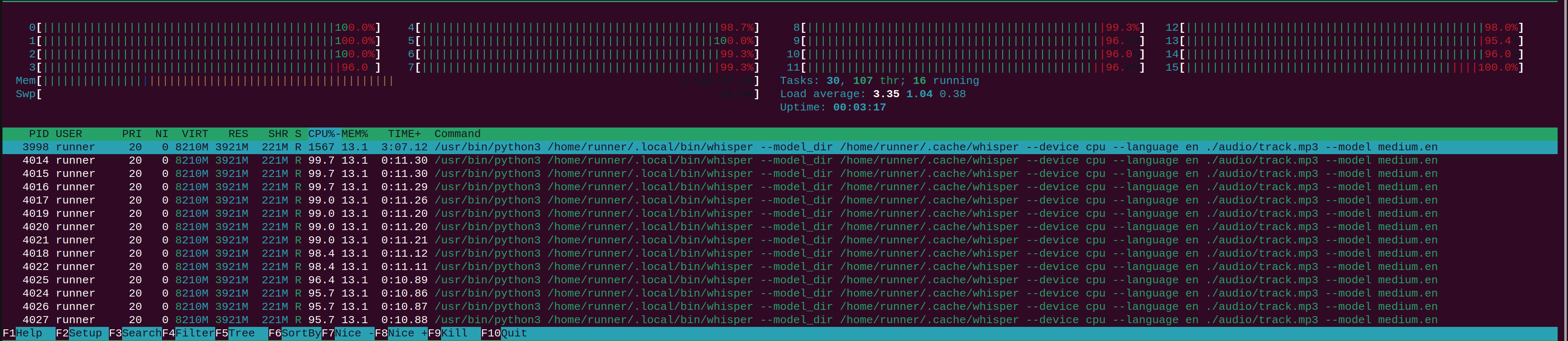
You can run the medium model on CPU, but would you want to?
With the medium model:
- The CPU took 8 minutes 54 seconds, pinning 16 cores at 100%
- The GPU took only 55s with very little CPU consumption
The GPU increased the speed by 9x, imagine how much quicker it'd be if you used an Nvidia 3090, 4090, or even an RTX 4000.
If you want to just explore the system, and run commands interactively, you can use actuated's SSH feature to get a shell. Once you know the commands you want to run, you can copy them into your workflow YAML file for GitHub Actions.
We took the SSH debug session for a test-drive. We installed the NVIDIA Container Toolkit, then ran the ollama tool to test out some Large Language Models (LLMs).
Ollama is an open source tool for downloading and testing prepackaged models like Mistral or Llama2.
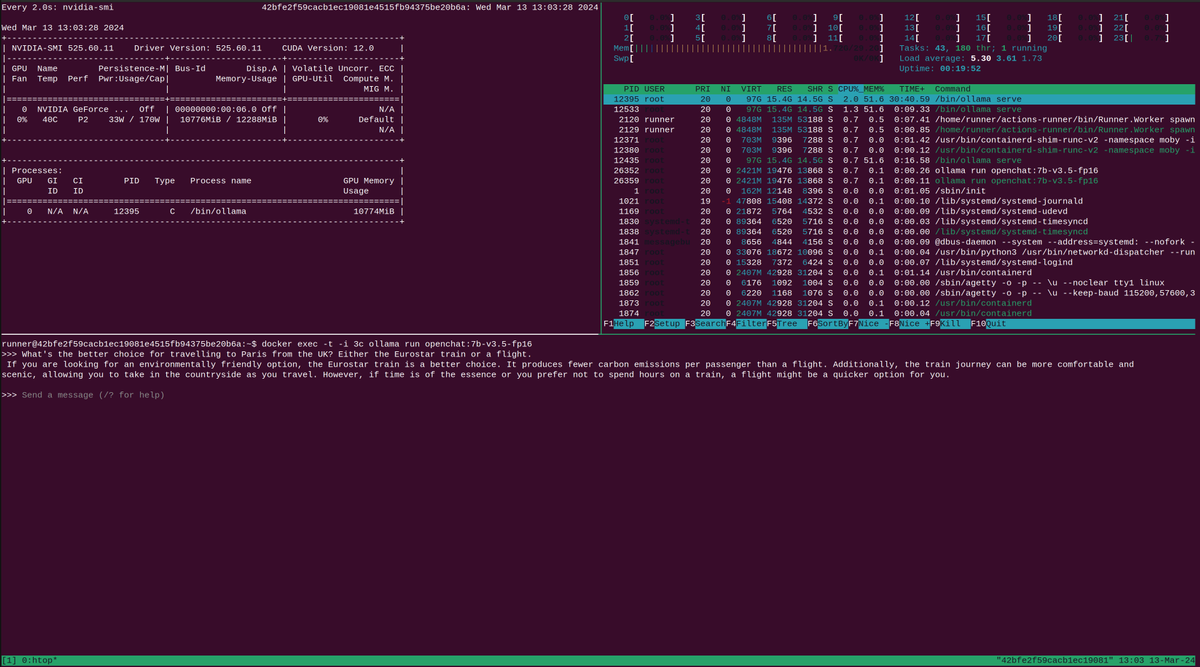
Our experiment with ollama within a GitHub Actions runner
The technical details
Since launch, actuated powered by Firecracker has securely isolated over 220k CI jobs for GitHub Actions users. Whilst it's a complex project to integrate, it has been very reliable in production.
Now in order to bring GPUs to actuated, we needed to add support for a second Virtual Machine Manager (VMM), and we picked cloud-hypervisor.
cloud-hypervisor was originally a fork from Firecracker and shares a significant amount of code. One place it diverged was adding support for PCI devices, such as GPUs. Through VFIO, cloud-hypervisor allows for a GPU to be passed through to a VM in a dedicated way, so it can be used in isolation.
Here's the first demo that I ran when we had everything working, showing the output from nvidia-smi:
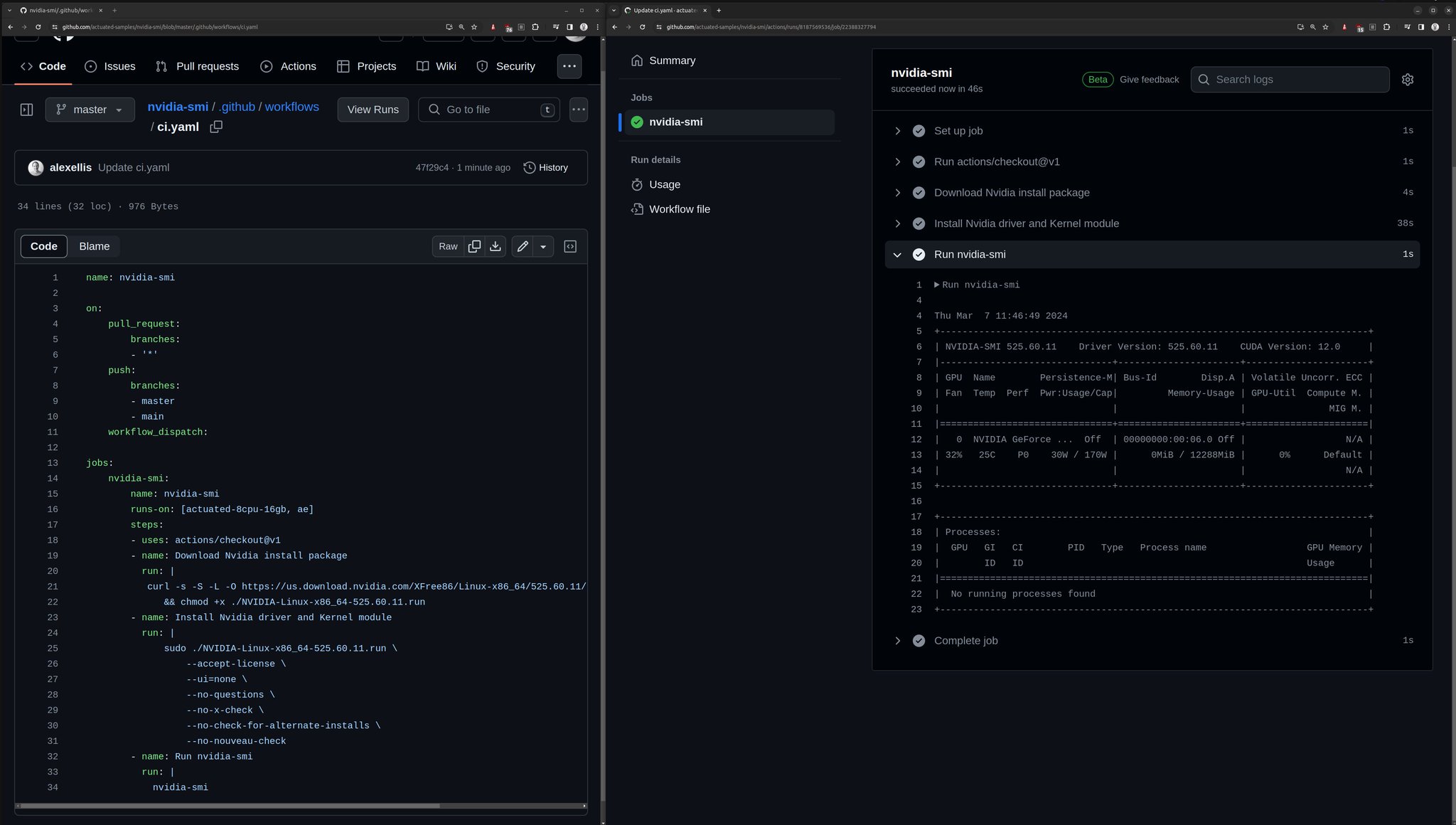
{kind=link}
The first run of nvidia-smi
Reach out for more
In a relatively short period of time, we were able to update our codebase to support both Firecracker and cloud-hypervisor, and to enable consumer-grade GPUs to be passed through to VMs in isolation.
You can rent a really powerful and capable machine from Hetzner for under 200 USD / mo, or build your own workstation with dual graphics cards like our demo rig, for less than 2000 USD and then you own that and can use it as much as you want, plugged in under your desk or left in a cabinet in your office.
A quick recap on use-cases
Let's say you want to run end to end tests for an application that uses a GPU? Perhaps it runs on Kubernetes? You can do that.
Do you want to fine-tune, train, or run a batch of inferences on a model? You can do that. GitHub Actions has a 6 hour timeout, which is plenty for many tasks.
Would it make sense to run Stable Diffusion in the background, with different versions, different inputs, across a matrix? GitHub Actions makes that easy, and actuated can manage the GPU allocations for you.
Do you run inference from OpenFaaS functions? We have a tutorial on OpenAI Whisper within a function with GPU acceleration here and a separate one on how to serve Server Sent Events (SSE) from OpenAI or self-hosted models, which is popular for chat-style interfaces to AI models.
If you're interested in GPU support for GitHub Actions, then reach out to talk to us with this form.